I heard about a recent conference called “Modern Data Stack 2021” which seemed interesting. I watched some of their talks and learnt quite a bit. My notes below.
Fantastic data products and how to build them (video link)
by engineers from 4Mile Analytics and Betterhelp
- A data-product will enable data driven decisions by providing a highly customized, action-oriented experience.(not just viz)
- Requires as foundation a well governed, trustworthy data stack
- Usually companies uses 3rd party BI tools, sometimes they need to go beyond that for a customized internal UI
- Demo at https://demo.4mile.io/ (showing truck traffic via IoT data from trucks)
- Demo app has notifications, has a clickable action to message truck driver, along with visualizations
- It also includes an embedded Looker dashboard
- Core tenets: i) Empathy ii) Trustworthy iii) Agility iv) It’s a Product
- Betterhelp is building an app around these principles
- They’re using dbt as a core piece
- They have tests and documentation for all their models
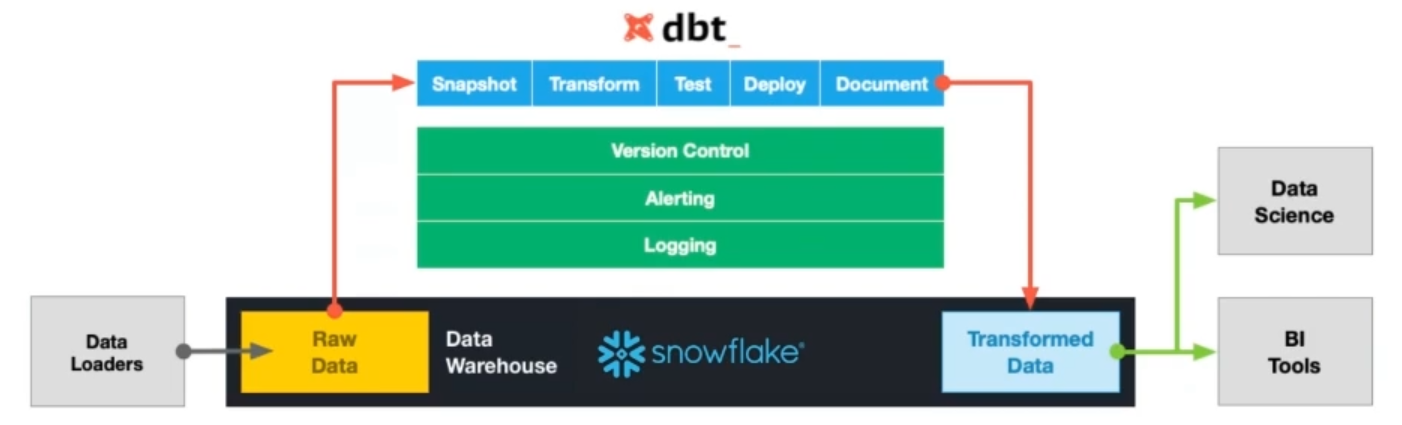
- Nice lineage view is available for dbt transformation pipelines (solves a big pain point)
- Design patterns: version controlled, democratized biz logic and data modelling, proactive alerts, data and schema testing, observability
What Modern Data Architecture is, really? (video link)
by an architect at Snowflake
- Data Arch has got stagnant and uses outdated patterns
- Data gets siloed in large orgs
- The shift to Cloud data platforms enabled SQL and fast answers compared to on-prem Hadoop
- Snowflake: Enable SQL and single platform for all use cases (avoid silos)
- We created data cubes because the data warehouse can’t scale
- Then we scaled data warehouse using file based data lakes
- Then Spark-like systems operate on subsets of files and create their own cubes. Again, leading to silos.
- Snowflake is the one platform to support all your workloads
Your next data warehouse is a Lakehouse (video link)
by two data architects from Databricks
- More companies are having to become data companies, and their data maturity levels are still low
- There is a fragmented landscape of data tools, your data too ends up getting siloed as a result. Other side effects are data discrepancies, issues with governance
- Data lakes and warehouses are complementary, with different benefits
- Data lakes are good to do ML on – support for different formats, unstructured data. Note that fundamentally you’re working at file level
- Warehouses are great for tabular style BI but not for ML
- Unifying the two would be great. This is what Delta Lake does!

- DL brings data mgmt and governance to data lakes
- You don’t work at file level though
- Supports indexes which makes queries many many times faster
- Databricks DL is open standards and open source
- It’s collaborative across teams
- Fivetran + dbt + Databricks is a good combo for a modern data stack
- Databricks SQL allows customers to have data warehouse performance on top of their DataLake. They’ve built a vectorized SQL engine called Photon in C++. It leverage SIMD chips.
- Databricks SQL also has a Serverless Compute offering. They can spin up a new cluster in 15 seconds. No need for you to do capacity management and allocate resources
- Some optimizations on how BI tools interact with Databricks through SQL
- There are improvements on the ML side
- AutoML is a transparent way to generate baseline ML models. You only need to indicate which column in a DataFrame you need to predict
- Feature Store improvements
How to accelerate analytics with a modern approach (video link)
by engineers from Sisudata and Fivetran
- Transformation is a high value activity
- We’re in the “information collection” age, not yet in the “information age”
- dbt focuses exclusively on transformation
- dbt handles transformation entirely within the data warehouse – there’s no extract or load
- Analysts can express their transformation in code (SQL)
- It is designed around SQL files, YML and an open source Python package
- The transformation process is idempotent
- Helps analysts iterate, re-rerun etc esp as schema gets updated
- It’s a hard concept to wrap your head around, and took him weeks too
- Sisu is a decision intelligence platform focussed on speed of end-to-end results
- dbt packages include bundled analytics and other transformations: That’s game changing, Two lines of code to start integrating hubspot data!
- A new fivetran feature is Integrated Scheduling with dbt
Fivetran Future Roadmap (video link)
by the VP of Product at Fivetran
- Fivetran has 200 engineers
- Highest priority is reliability of data delivery
- Column masking
- Mirror GDrive etc folders into warehouse tables
- Links through VPC without using public internet. All data encrypted at rest and in motion using customer’s keys!
- Facilities to onboard customer data from external sources
- Integrated scheduling with dbt core
- They’ve built many prebuilt data modelling packages (linkedin, jira, youtube, salesforce etc)
New Kids on the Block (video link)
A 5-minute presentation each from a bunch of startups
- Firebolt – firebolt.io
- Platform for all analytics workloads
- Users: data engineers and developers
- Eg: SimilarWeb crunches over 200TB in seconds!
2. Hex – https://hex.tech
- Collaborative analytics workspace (Python + SQL + UI)
- Can generate interactive data apps
- Eg: 60+ users across teams are collaborating one customer account
3. Materialize – https://materialize.com/
- Simplest way to get started with streaming. A simple fast SQL streaming experience
- Built from the ground up as a streaming database to enable streaming analytics
- SQL is Postgres compatible
- Also available as a cloud product
- Eg: A financial services firm need quick, heavy queries on OLTP data. Materialize let them join data in Kafka with data in Postgres!
4. Transform – https://transform.co/
- (Business) Metrics store
- Enables data analysts to define consistent metrics across all of a company’s products. Enables metrics governance at scale.
- They believe inconsistencies in metrics is a key problem in making data accessible
- Eg: Netlify is a customer
5. Select Star – https://selectstar.com/
- Automated data discovery tool
- They gather usage stats to know most frequent columns, tables etc
- You can search across all database and BI tools
- There is Lineage, tagging
- Eg: Pitney Bowes company uses Select Star as a metadata management tool
6. Treeverse – https://treeverse.io/
- Git like repository for data objects
- Eg: SimilarWeb is using Treeverse to manage data related to ML experiments
7. Tellius – https://www.tellius.com/
- AI Driven Decision Intelligence problem
- An AI layer sits on top of data, queries can be via NLP
- Use cases: Segmentation, anomalies
- You can get subsecond response for adhoc queries at scale
- Eg: A Fortune 10 company was able to figure out why high loan delinquency rates were happening
8. Atlan – https://atlan.com/
- Collaborative workspace for moden data teams
- i) Reusability of data assets ii) Lineage iii) Embedded collaboration (URLs for data assets etc)
- Eg: Unilever got more visibility into their data lake and use Atlan as the portal to that